
TL;DR: I ran my Refactoring towards Clean Architecture workshop at SymfonyLive Berlin 2026. Smaller room than my previous workshops, but the energy and engagement were top tier. I changed the formula a bit — more theory, more group exercises, more whiteboard work — and I think it landed. Below: what I changed, what the attendees asked, and a big thank you to everyone who made it happen 🙌

Short reflection
This was my third time running Refactoring towards Clean Architecture at a Symfony conference, after SymfonyCon Amsterdam 2025 and SymfonyOnline 2026. And I have to say — every edition feels different.
Berlin gave me a smaller group than the previous two editions. At first, I was slightly worried — fewer people, more pressure on each conversation to carry weight. But it turned out to be a gift 🎁 The group was incredibly active: thoughtful questions, real opinions on architecture trade-offs, and a willingness to push back and discuss. Exactly the kind of room I love teaching in.

What I changed in the format
A smaller group also meant I could afford to slow down and rework the structure. Two main changes:
1. More theory, less rushing into code
In the previous editions, I was always racing to get to the coding part. This time, I gave the theory section more space— not because theory is more important than code, but because without solid mental models, the code refactoring feels like cargo-culting. You move things around, but you don’t know why.
2. A group exercise on primary vs secondary actors
This was the biggest experiment of the day, and I think it paid off.
Hexagonal Architecture talks about primary (driving) and secondary (driven) actors and ports/adapters. On paper, this sounds simple. In practice, people often blur the two and end up with a confused dependency graph.
So we did the following:
- I drew our application in the centre of the whiteboard.
- We listed every external thing around it — a user, a controller, a database, a message broker, an external API, a scheduler, a CLI command…
- For each one, we asked together: Is this primary or secondary?
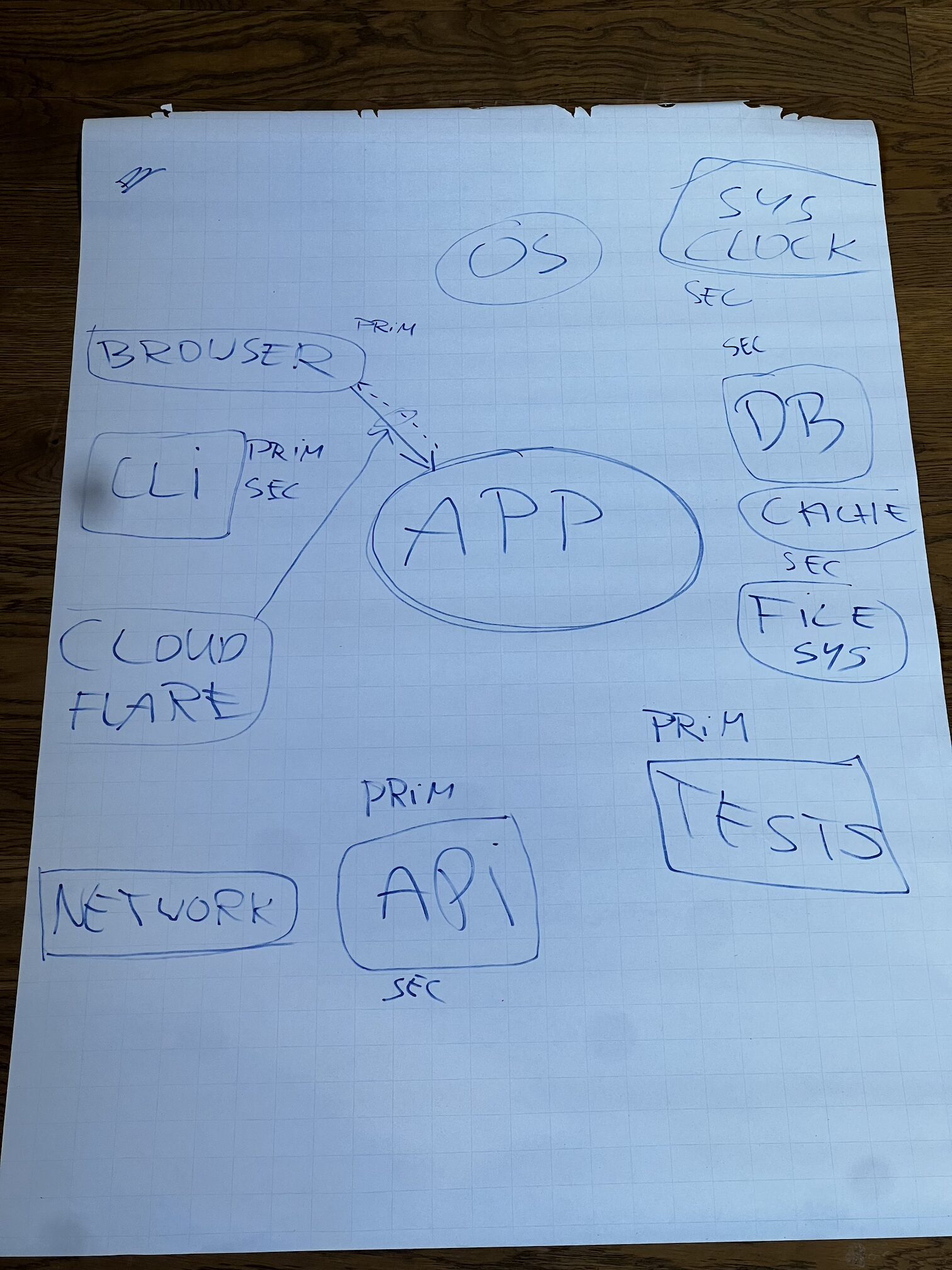
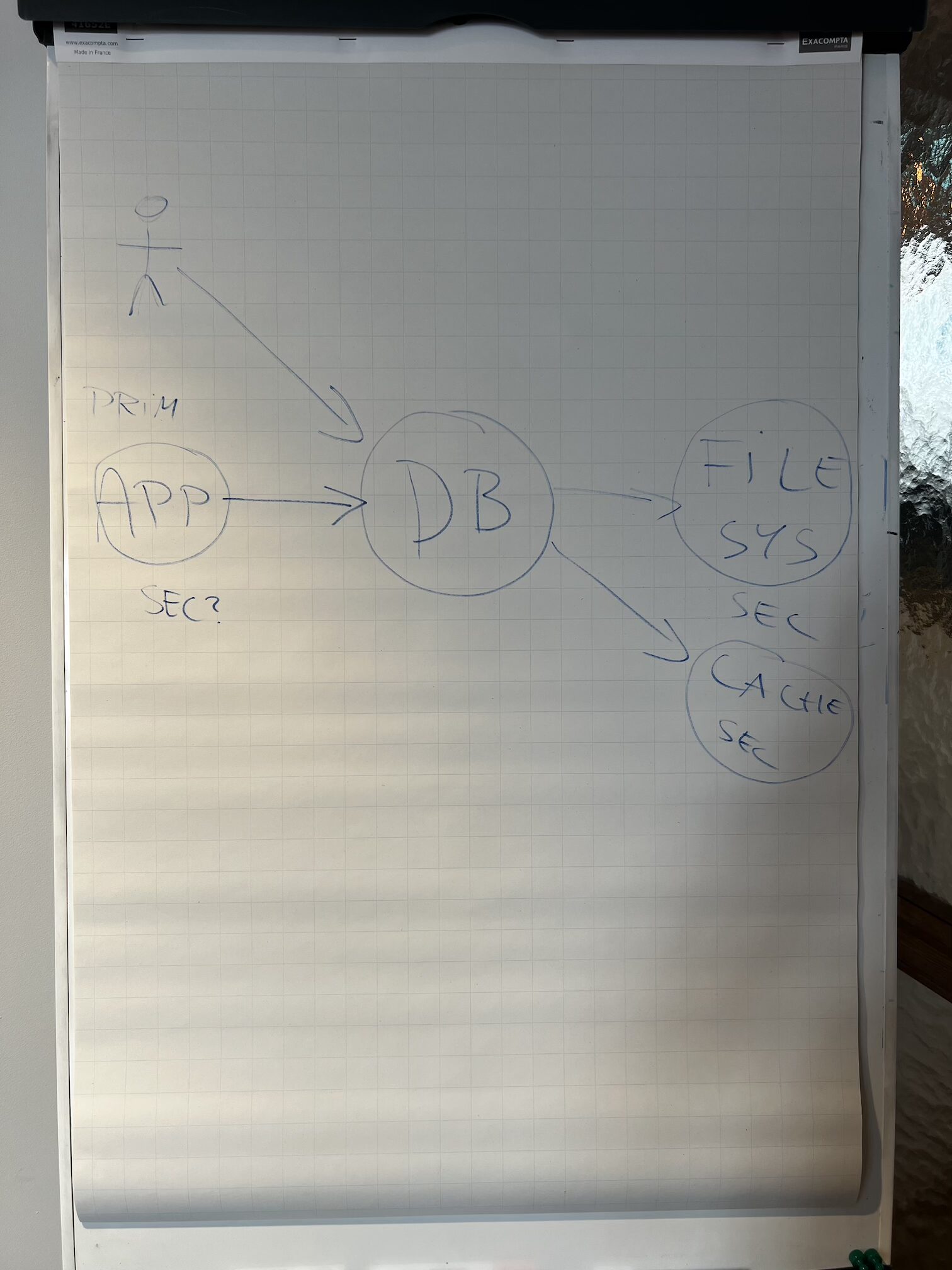
Then — and this is the part I was most curious about — we flipped the perspective. We treated the database as the centre, and asked the same question about its external collaborators (including our application). Suddenly, things that seemed obviously “secondary” from one angle became “primary” from another. That perspective shift is what makes hexagonal click. From the application’s point of view, the DB is a secondary actor. From the DB’s point of view, the application is a primary actor calling it.
I really wanted that to land for the group, and judging by the discussion that followed, I think it did 😊
3. Coding together on the big screen
The original plan was: theory → live coding → exercise on your own machine. But after the theory and the group whiteboard exercise, the group made an interesting suggestion — let’s code together on the big screen, follow your steps, and we’ll repeat the exercise on our own machines later as homework.
I love this kind of feedback. It gave us more time for discussion during the coding part, and removed the pressure of “did I copy that snippet correctly”. Of course, the trade-off is that the muscle memory comes later, on the homework — but that’s a fair deal.
One thing I keep repeating: architecture is a trade-off
Throughout the day I tried to be very explicit about one thing:
Everything we’re doing today is one possible way. Not the only way, not even necessarily the best way for your context. Architecture is always a trade-off, so always ask whether this approach makes sense for yourproblem.
If there’s one thing I’d like attendees to walk away with, it’s this. Patterns and architectures are tools, not commandments. Use the ones that solve a real problem you have.
What the participants said
I always run a small post-workshop survey. From the responses I got:
- Everyone said they enjoyed the workshop ✅
- Ratings were 4 and 5 out of 5 🌟
- Two pieces of feedback I want to highlight publicly, because they’re fair and useful:
- Go a bit slower during the coding sessions. Noted — I’ll plan more buffer next time.
- Give attendees 10–15 minutes to try a task on their own before showing the solution. This is great advice. Even when the group agrees to follow along, having that initial “struggle window” builds way more understanding than watching someone else type.
- Also — somebody pointed out a typo in the README. Fixed 😅 Thank you for that one.
This kind of feedback is gold to me. If you were in the room and didn’t fill the survey out — it’s never too late, ping me 🙂
Questions & Answers from the workshop
A few questions came up that I think are worth sharing more broadly.
1. Does it make sense to extract an interface for the Use Case?
As we discussed during the workshop — it depends 🙂
If you want to test your primary adapter (e.g., a controller) independently and fast, having an interface for the use case is the way to go. You can mock it, drive your adapter tests with predictable behavior, and skip booting the whole application.
There’s a second, more architectural reason: an interface gives you a clear boundary around your use cases. The interface becomes an abstraction over the use case layer, and abstractions are how you draw lines in your codebase.
If you don’t have either of those needs — testing speed or boundary enforcement — then no, you probably don’t need it.
2. What is the value of using read-models (DTOs) instead of entities?
This is essentially how you start implementing CQRS in a pragmatic way.
In a simple application with anemic models, returning entities directly from your read-side is fine. There’s no domain logic to leak, and the entity is basically a row of data anyway.
But once you have a rich domain model with invariants, behavior, and internal state, the use case layer should (not must) work with read-models / DTOs. Why?
- You don’t accidentally expose mutable domain state to the outside world.
- You can shape the read-model exactly for the consumer (UI, API, report).
- Your reads stop being constrained by your write-side aggregate boundaries.
It’s about giving the read-side and the write-side the freedom to evolve separately.
3. Why create a new directory/namespace for the refactored code?
This is essentially the strangler fig pattern applied at the codebase level.
Three reasons I like it:
- A bold line between legacy and new code. No ambiguity about which side a file belongs to.
- Motivation. Watching the new namespace grow while the legacy one shrinks is genuinely satisfying. It’s a visible progress bar for your refactoring.
- Navigation. When you open the project, you see immediately what’s refactored and what isn’t. No archaeology required.
4. What do we do once everything is refactored out of the legacy folder?
First — celebrate 🎉 Seriously, that’s a milestone worth marking.
I think the real question behind this one was: what about the new namespace? Do we keep it, or rename it back?
It’s up to you. You can leave it as is, or you can do one big rename to fold the new namespace into the original one. Just be aware: that final rename will be a massive pull request with a lot of moved files. Coordinate with your team, do it on a quiet day, and prepare for some merge-conflict gymnastics 🤹
Thank you 🙌
To the SymfonyLive Berlin organisers
Every time I attend a Symfony conference — Amsterdam, Online, and now Berlin — I’m struck by the same thing: the openness, friendliness, and genuine welcome that runs through the whole event. It’s not marketing copy, it’s real. Speakers, attendees, organisers — everyone treats each other like part of the same community. Thank you for keeping that culture alive.
To the other speakers and trainers
Spending time with you between sessions, at speaker dinners, in hallway conversations — that’s where I learn the most. Thank you for being generous with your time and ideas.
A note on “paying back”
I use open source every single day at work, and Symfony is a huge part of that. I’m not a core contributor — I don’t have the bandwidth for that right now — but running these workshops at Symfony conferences feels like my way of giving something back to a community that gives me so much. If a few engineers leave the room with a cleaner mental model of architecture, that’s a small thank-you to the people who make the framework possible 💜
To the attendees
You showed up on a workshop day, asked sharp questions, pushed back where you disagreed, and committed to doing the coding as homework. That’s exactly the kind of group that makes a workshop worth running. Thank you 🙏
A few words about Berlin
This was my first time in Berlin, and I really liked the city. The thing that surprised me most was the bike culture — it’s not Dutch level (Amsterdam still wins this contest 🚲🇳🇱), but it’s seriously high. Wide bike lanes, drivers who actually respect them, lots of people commuting on two wheels. As someone who appreciates well-designed urban infrastructure, this made me very happy.



I’ll definitely come back.
Final thoughts
Three editions of this workshop now, three very different rooms, three different formats. Each time I learn something I want to bring into the next one. From Berlin I’m taking:
- The two-perspective whiteboard exercise for primary/secondary actors — this stays.
- More time buffers in the coding section — fix this.
- A “try it yourself first” window before live-coding — try this next time.
If you were at the workshop, thank you 🙏 If you weren’t but you’d like to be at the next one, I’ll keep posting updates on my talks page and on LinkedIn.
See you at the next conference 👋